Audio Analysis with Deep Convolutional Neural Networks
My MSc thesis describes an approach for automatically classifying audio signals using an automated machine-learning system implemented with the Google Tensorflow machine learning library.
Thesis download: Automated Audio Content Analysis with Deep Convolutional Neural Networks by Elisabeth Anderson
For the last three years I’ve been working on an MSc in Software Engineering and Internet Architecture in conjuction with BBC Academy and Bradford University. My thesis was in deep machine learning and covered automatic audio content analysis using deep convolutional neural networks implemented with Google Tensorflow.
Project River is a prototype built as part of this thesis to analyse pre-classified audio samples from radio broadcasts and use these to build a Convolutional Neural Network to predict the audio classes when presented with further samples from radio broadcasts. This research is to determine if Convolutional Neural Networks are an appropriate method of classifing audio.
River uses Google’s TensorBoard open-source Machine Learning library and Librosa to analyse audio signals.
My research analysed audio samples from BBC broadcasts and attempted to predict a classification for these samples which would enable a machine learning system to learn and predict the actual content of audio broadcasts. Audio samples are such as:
 Waveform Plot of R&B Track
Waveform Plot of R&B Track
 Spectrogram Plot of R&B Track
Spectrogram Plot of R&B Track
 Waveform Plot of Speech
Waveform Plot of Speech
 Spectrogram Plot of Speech
Spectrogram Plot of Speech
Modern radio playout systems are able to produce metadata to support broadcast audio. This can include start and end points for tracks played, studio microphone activations, and timings for news broadcasts. This metadata relies on studio equipment supporting the generation of this metadata and is restricted to only the types of metadata built into these systems. This thesis describes an approach to generating metadata from a raw audio signals using an automated machine-learning system to augment broadcast audio with metadata about the content of the audio. Audio fingerprints as Mel-frequency Cepstrum Coefficients (MFCCs) were generated from raw 4-second duration WAVE audio samples. These 1-dimensional tensors were used to train a Deep Convolutional Neural Network (CNN) classifier using the TensorFlow machine learning library with two convolutional layers, rectified linear activation unit (ReLU) activation functions, a fully-connected layer, pooling, and dropout. This model was validated against previously unseen audio fingerprints and classified audio with a 71% accuracy. The conclusion of this research was that CNNs were classifiers without requiring in-depth knowledge of audio theory and signal processing.
In the last few years the pace of research has increased in the field of deep learning and some promising results applying this approach to image analysis and classification. Research is also currently focusing on analysing audio signals using this deep learning approach Piczak (2015) with promising results for types of audio including music Lee et al (2017) and Oord et al (2013), environmental audio such as footsteps, baby crying, motorcycle, rain Gencoglu et al (2014) and Piczak (2015) and also recognising bird species from audio samples Piczak (2016). Although machine learning using traditional back-propagated neural networks has attempted to solve the types of problems discussed in this paper it is clear that deep learning has already had some considerable success. Goodfellow et al (2016) explain, “It is not entirely clear why CNNs succeeded when general back-propagation networks were considered to have failed. It may simply be that CNNs were more computationally efficient than fully connected networks, so it was easier to run multiple experiments with them and tune their implementation and hyperparameters”. It is this computationally-efficient nature of deep learning that will be leveraged to build a learning system to classify audio signals.
The performance of the system was represented as accuracy and cross entropy.
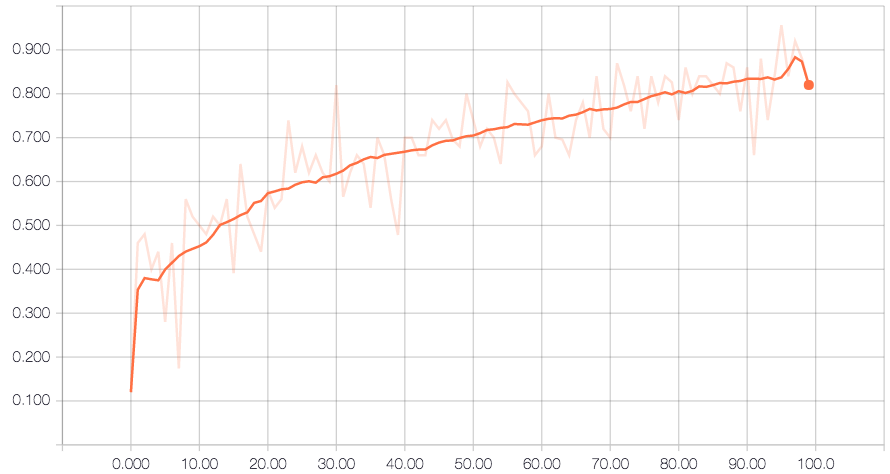 Accuracy Plot
Accuracy Plot
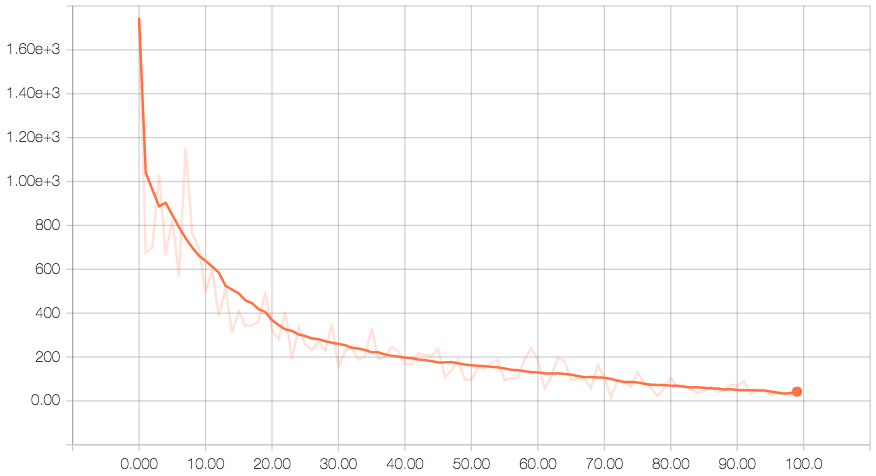 Cross Entropy Plot
Cross Entropy Plot