Delivering with GCP at the BBC
There probably is a software engineer’s equivalent of the Rifleman’s Creed and it’s probably something like…
This is my infrastructure stack.
There are many like it, but this is mine.
So, this is ours… but first, some context.
Having been at the BBC for 9 years I’ve seen a few major changes in infrastructure. When I started, our process was largely to edit HTML and Javascript locally and FTP the changes up to the live server. The live servers were the source control and to make a change a Web Developer would copy the live site and update it, then send it back again. I’m not sure if I’m actually allowed to fully recount one of the stories of that time but suffice to say the Wayback Machine is a good method to recover lost HTML…
At this time we also built Rails apps and hosted these on our own on-prem infrastructure and had a great Rails team. Incidentally, it was a Rails App that powered my first BBC project; Visual Radio.
The next big shift-change was to a platform called Forge. This supported Java services, implemented usually in Spring, and PHP web applications, implemented with frameworks such as Zend. On the journey to a mature software organisation this was a time that many found restrictive but it supported the organisation in defining process and control over how we deliver features to our audience.
Shortly after we had finished migrating all of our apps to Forge, we started building new apps in the cloud with Amazon Web Services. To support this new platform we developed a system called Cosmos which acts as a delivery shim between the engineering and delivery teams at the BBC and the cloud provider. This provides a mechanism by which we can safely and, with relatively low friction, release to our cloud services provider and the audience. Cosmos also provides secure VMs, rollbacks, and a host of other benefits.
Let’s skip to the present and, 10months ago, I joined a fledgling team at the BBC called Datalab, a team tasked with bringing together what we know about our content into one place and using machine learning to enrich it. Not only did we have our own roadmap of products to deliver but—as we were a greenfield project without any legacy—we would also move into Google Cloud Platform (GCP). We arrived at GCP with no infrastructure and no legacy so set about defining how we’d use this new platform.

‘Data visualisation’ during the 1951 general election.
Previously, to build an API, we’d typically employ an architectural pattern of some application code (such as Scala), implemented with a framework (such as Akka), running in an application server (such as Spray or Akka HTTP), packaged as a binary (such as an RPM package), deployed onto a snapshot machine image (such as CentOS 7), deployed as a VM (such as an EC2 instance), running behind a load-balancer (such as an Elastic Load Balancer) [see fig 1.]. Usually we’d have a set number of these instances running and scale out under increased load. We’d follow the maxim of scale out fast, scale in slowly to benefit from the overhead and cost of spinning up new instances. It takes in the order of large values of seconds to small values of minutes to scale out.

Fig. 1 — API stack
To deploy a new feature we’d check the feature into our Git repository, then the build pipeline would be triggered. This would build a new VM for us, with our application binary baked in. We could then deploy to our pre-production environments using a rolling deployment which replaced the VMs with a new instance one by one. After running our smoke tests we’d promote this to production, again using a rolling deployment. If the smoke tests failed we’d rollback by pushing an older, known to be working, version of our application.
Moving into GCP allowed us the opportunity to re-think our stack and the first thing on our list was to benefit from containers. Let’s deftly skip over why containers are a good idea but they were a great fit for our project; a system built using microservices.
We also made the decision to move to Google Kubernetes Engine (GKE) as our container orchestrator. This means our containers need only be declared as workloads and GKE will make this request a reality. We can benefit from autoscaling in our Kubernetes (K8s) cluster and benefit from another optimisation; swapping HTTP internal traffic to RPC. Rather than our components being deployed in a VM and communicating via HTTP our pattern now is to have external HTTP(S) ingress and internal RPC communications. We implemented this with gRPC.
The choice of language in the implementation of any component is important for an organisation and we decided to use Python as our house language. This is mostly because our team comprises of a number of different roles such as data scientist, data engineer, and software engineer but we all have Python in common—and we think it’s important that everybody can work on all parts of the system. Our containers run Flask/Green Unicorn for HTTP and gRPC Protocol Buffers for RPC. Compared to a full VM, we can scale out in seconds—especially due to each container having a lightweight parent based on Alpine Linux and the actual container layer is very small.
We now have containers and a cluster to put them on [see Fig. 2], but we needed to think about how we delivered features to production. One of our goals is the potential to release a feature on the first morning you join the team. This means there should be no complex processes, no restricted access, no arcane knowledge, and no hierarchy.
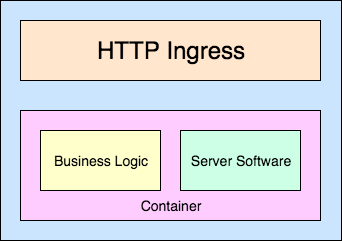
Fig. 2 — Container Application Structure
Firstly we merge features we wish to release into our Git repository. This triggers our Continuous Integration (CI) pipeline (in fact any commit to any branch does). To run our CI we use Drone and define a pipeline for each component. With Drone we can run our automated testing and validate the containers we’re building. Our repos are then in a constant state of healthy or broken (which inhibits a release).
To release that feature we tag it, which triggers Google Container Builder to build our image and push it to our Container Registry.
At this point our Continuous Delivery (CD) tooling takes over, triggered by the presence of a new version of a container. To run our CD we use Spinnaker which runs our delivery pipelines. These pipelines define how a microservice should be deployed into the cluster. Typically we deploy automatically into the cluster to our stage environment (more on that later) and then send a message to our team’s Slack channel to let us know a deployment is ready to be promoted. Our smoke tests are then run and the feature promoted to production.
These deployments run as a green/blue deployment (or red/black in Spinnaker/Netflix parlance). So instead of performing a rolling update of replacing node by node, we spin up a mirror deployment on our cluster and switch the service from the old deployment to the new using traffic splitting. This means that the previous deployment is still running and we can slowly bring a new feature into service and run canary tests while this is happening. If we experience any issues we can simply send the traffic back to the old deployment without any issues. We leave the previous deployment running, but disabled, until we’re confident the new deployment is operating correctly. Google also recently announced the availability of Kayenta on the platform which provides automated canary analysis tooling.
We generally run two environments; stage and production. However, because we run everything on a K8s cluster these environments can be as similar to each other as we need them to be; we don’t have a pre-production environment which is markedly different to production. These environments are deployed as versions of a Kubernetes service. So each container, say foo-service, is deployed as a Kubernetes service foo-service-stage and foo-service-production. This approach allows us to deploy interim environments too, for experiments etc. So foo-service-experiment-bar environments are possible too.
Our microservices communicate via RPC but to provide HTTP ingress we use a Kubernetes Ingress Controller which accepts HTTP, terminates the TLS connection, and forwards to our service within the cluster. This is implemented with a Google Cloud Load Balancer and provides secured ingress to our cluster.
We’re not replacing our VM strategy but adding more deployment options to our enterprise. While this post started with a story of how far we’ve come in the last few years, I’m sure that if we check back in a few months things will have continued to change and move forward at an ever-increasing rate at a velocity that’s well supported by our infrastructure and tooling.
Originally published at How we deliver with GCP at the BBC on the BBC Design + Engineering Blog at Medium.